英伟达(Nvidia)与AMD在AI领域的技术竞争力对比
Nvidia无疑是今年美股最亮眼的星,从100多涨到500多,战胜了所有看好Nvidia但科班出身非要分散投资的账户(包括笔者),诠释了看准了一把梭才是投资的最高境界。
Nvidia的涨幅,可谓天时地利人和的产物,首先是ChatGPT带动的AI热潮,然后是突发起来的市场需求结合半导体需要近一年以上设计到量产的周期,导致市场上只有Nvidia的芯片可用,创造了H100高达90%毛利率的商业奇迹。
可以说截至目前除了Nvidia,包括微软和OpenAI在内,对AI都是投入期,钱全部被Nvidia赚走了,因此市场上冒出来一大堆的竞争者,我们从技术角度做一个简单的对比,以最强挑战者AMD为例来检验Nvidia的护城河有多深。
此文跳过基础的介绍,如对Nvidia不够了解建议先从之前文章《来钱系列:英伟达展望—写在Q2财报前夕》开始阅读。
首先没有平级的竞争对手,因为CUDA生态
Nvidia CUDA早已成为事实工业标准,而竞争对手至少与其有10年的差距,AMD再造一套标准和生态已然不切实际。因此,AMD在机器学习方面的权宜策略就是兼容并学习CUDA,管理学上叫引进-消化-再创新。AMD GPU软件栈首先要做的就是实现API兼容,通过这种方式将诸如Tensorflow/Pytorch等等已经针对CUDA API/libs/tools/drivers做过适配调优的DL Framework整体兼容到自家GPU卡,并兼顾对齐了CUDA生态资源(为此需要针对CUDA提供极便利且持续的开发者友好性)。
那么如何实现这种兼容呢?这个项目叫作“ROCm - Radeon Open Compute Platform”(Radeon锐龙就是AMD显卡品牌),是通过二进制翻译/进程虚拟机技术去解析和转换CUDA PTX通用指令到Radeon指令--这里注意PTX并非真实的NV GPU硬件ISA,而是向上封装的伪代码层(Virtual Archiecture)。
基于ROCm翻译实现“CUDA兼容的AMD GPU”所面临的掣肘是显而易见的:工具链匮乏、库资源匮乏、开发和迭代兼容性的代价较大,以及难以发展自有生态。在机器学习场景中,就如流行的Pytorch框架也难以更好的支持A卡加速,因此并非AMD GPU不能加速机器学习任务,而是开发工作十分勉强且在迭代和生态延展性方面不可取。
在Non Nvidia CUDA的阵营里,还有一些发展中的方案用于AI加速但一样构不成威胁:
OpenCL:当年由AMD/Apple等厂商共同发起的工业标准,历史悠久,道阻且长;虽然生态弱于CUDA,但至少可运行一些ML加速的代码,掣肘之一仍是无法支持Tensorflow/Pytorch等流行框架,以及开发难度高,环境不友好;
MSFT的某项目,号称支持A卡加速:GitHub - microsoft/antares: Antares: an automatic engine for multi-platform kernel generation and optimization. Supporting CPU, CUDA, ROCm, DirectX12, GraphCore, SYCL for CPU/GPU, OpenCL for AMD/NVIDIA, Android CPU/GPU backends.
CUDA生态的护城河已经很难逾越,不仅是软件栈的优势,还包括NV每年每代硬件产品发布时伴随更新的指令、算子和加速库/数学库,于是CUDA版本更新便会加入这些特性以及加入针对新硬件特点的支持;这种闭源更新的模式对于“那些硬件独立发展但软件栈生态保持追随CUDA的厂商”而言是极为捶胸顿足的。
2023年3月的Nvidia GTC发布会再次刷新了100个算子;做CUDA兼容,最担忧的是NV每年刷一遍算子和新指令,尤其这代算子很多都是针对Hopper硬件新架构的特性而设计,模仿不来。想想AMD MI250计算卡的销量惨淡,其中一个原因就是算子不兼容,其ROCm虚拟机道路走得极累,且并未100%实现。INTC同样是选择虚拟机/BT翻译的路线,还包括针对ARM+Android指令集的跨生态兼容,直到最终IBT/Houdini部门都被裁撤了。
AMD的发力点—内存
虽然生态上AMD难以取胜,但AMD还是卡在Nvidia从H100到B100的更新间隙,通过叠内存结结实实的恶心了黄仁勋一把,这也是AMD的一贯战略,就是跟随龙头的同时在龙头换代周期中间推出更具性价比的产品,但同时龙头厂商可以降低售价来打压AMD,导致AMD始终在老二的位置毛利上不去。
出于技术和经济原因,各种处理器在计算上配置过度,但在内存带宽上配置不足。因为内存容量取决于设备和工作负载。比如处理Web基础设施工作、或一些相对简单的分析和数据库工作,一个拥有十几个DDR内存通道的CPU就足够处理了。但对于HPC模拟和建模、人工智能训练和推理来说,这点内存通道就不够用了。为了实际提高矢量和矩阵引擎的利用率,内存容量和内存带宽突然成了高性能GPU的命门。
于是AMD下月6日举办的发布活动中,该公司将会发布Instinct MI300A和Instinct MI300X。Instinct MI300A为AMD首个集成24个Zen 4 CPU核心、CNDA 3架构GPU核心以及128GB HBM3的APU,其被认为在性能上有望与英伟达的Grace Hopper相媲美。
AMD的得益于过去多年花式玩chiplet,为了研发CPU,GPU和内存封装的灵活组合做的模块化设计。可以在市场需求发生LLM这种重大变化情况下迅速拿出一款更适合的形态出来。MI300原本是一个灵活组合的APU形态,4个SoC die上可以灵活选择放2个GPU die或者3个CPU die。其实APU市场定位比较尴尬的。而这次拿出的MI300X,4个SoC die全部选择放GPU。而8个HBM3的槽位也从16GB的规格升级到了24GB的规格。
Instinct MI300X集成了12个5纳米的小芯片,提供了192GB的HBM3、5.2TB/秒的带宽,晶体管数量高达1530亿。MI300X提供的HBM密度是英伟达H100的2.4倍,HBM带宽是H100的1.6倍,意味着在MI300X上可以训练比H100更大的模型,单张加速卡可运行一个400亿参数的模型。不过由于是临时拼凑的产品,苏妈重点强调了堆内存的优点而闭口不谈核心的算力。
而当时英伟达更换了架构的下一代GPU芯片B100要最早明年Q2才能发布。6个月的时间,一个更强的AMD显卡完全可能削弱英伟达的AI霸权。英伟达只能把内存升级到和MI300X同水准,靠半代升级截胡AMD。
于是在11月13日的2023年全球超算大会(SC23)上,英伟达发布了新一代AI芯片HGX H200,用于AI大模型的训练,相比于其前一代产品H100,H200的性能提升了约60%到90%。
H200是英伟达H100的升级版。与过往GPU升级主要都在架构提升上不同,H200与H100都基于Hopper架构。在同架构之下,H200的浮点运算速率基本上和H100相同。而其主要升级点转向了内存容量和带宽。具体包括141GB的HBM3e内存,比上一代提升80%,显存带宽从H100的3.35TB/s增加到了4.8TB/s,提升40%。
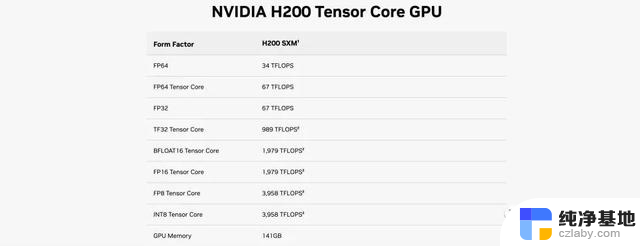
H200核心GPU运算数据与H100完全一致
然而,在大模型推理表现上,其提升却极其明显。H200在700亿参数的Llama2大模型上的推理速度比H100快了一倍,而且在推理能耗上H200相比H100直接降低了一半。对于显存密集型HPC(高性能计算)应用,H200更高的显存带宽能够确保高效地访问数据,与CPU相比,获得结果的时间最多可提升110倍。核心没变的1.5代产品,居然可以获得如此巨大的性能提升,可见内存对于AI运算的重要性。
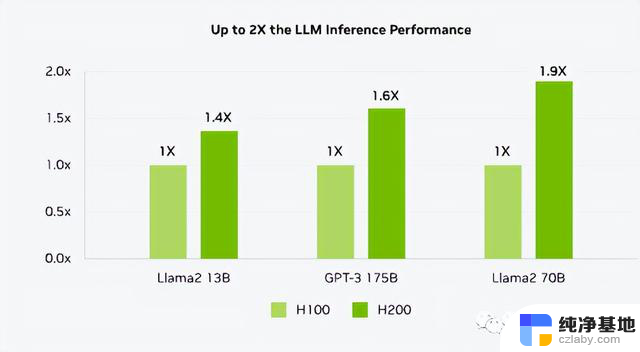
*这里英伟达耍了一个花招,在官网对比上,H200 SXM对比的是没有使用TensorRT-LLM的H100 SXM,TensorRT-LLM下文会讲。
王者英伟达也被迫卷起内存,而这额外的内存大概会提高1500美元采购成本,不过好在H100的生产成本只有3000美元而售价高达40000美元,H200如此巨大的性能提升老黄很轻易就可以把这点内存翻倍卖给用户。
我们顺便提一个不卷内存的反面教材——Azure Maia GPU
微软因为不甘心成为Nvidia最大的宿主而自研的Azure Maia GPU,虽然在算力方面能与英伟达H100和AMD MI300X一战,在网络I/O方面也有独到之处,但由于是在大模型热潮出现之前设计的,Maia的显存带宽只有1.6TB/s。虽然这比Trainium/Inferentia2高,但明显低于TPUv5,更不用说H100和MI300X了。

尴尬的是即便微软在芯片上加载了大量的SRAM,从而帮助减少所需的显存带宽,但1.6TB/s的带宽与H100堪称代差,并不适用于现在的大语言模型。
所以当记者问到跟H100、H200,甚至是AMD最新的MI300X比较,Maia的性能如何时,微软Azure 硬件系统及基础设施部门负责人 Rani Borkar 回避了这个问题,而是重申微软与英伟达和AMD的合作对于Azure AI云的未来很重要。—他也知道现在惹不起Nvidia,微软搞硬件还是一如既往的尴尬。
英伟达过去两年一次发布新GPU的节奏,给了竞争对手大好的机会抢夺市场。为了应对AMD的补漏战术,英伟达正在把产品周期加快到每年一次,不给对手任何机会。比如2024年便推出B100,2025年推出X100.....
英伟达的B100将于2024年第三季度量产,部分早期样品将于2024年第二季度出货。从性能和TCO看,无论是亚马逊的Trainium2、谷歌的TPUv5、AMD的MI300X,还是英特尔的Gaudi 3或微软的Athena,跟它相比都弱爆了。
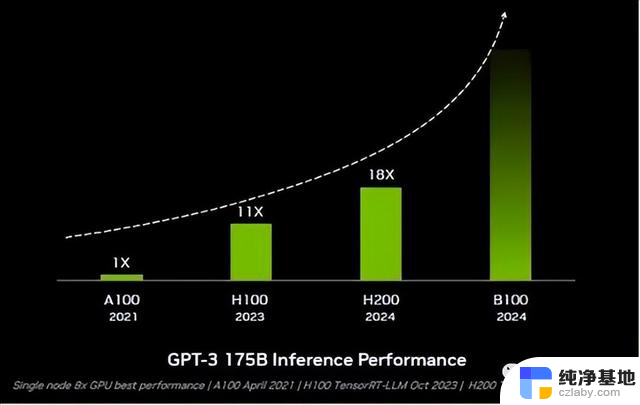
英伟达的秘密武器TensorRT-LLM
英伟达TensorRT-LLM是由TensorRT深度学习编译器组成,包括优化的内核、预处理和后处理步骤以及多GPU/多节点通信原语。TensorRT-LLM的工作原理类似于“高斯求和”的故事,别的小朋友还在算等差数列依次相加的时候,高斯直接掏出一个公式很快算出了结果。TensorRT-LLM就相当于是这么一个公式,以软件优化的方式帮助GPU快速解决复杂计算。以H100为例,使用TensorRT-LLM后的H100,在对一些媒体网站进行文章摘要时的工作效率,比使用前快出整整1倍。而在700亿参数的Llama2上,前者比后者快77%。这也是为什么AMD闭口不提Instinct MI300X的实测性能,就连算力也直接从核心指标里去掉了,因为即便硬件能堆出来优化软件也有着明显的差距。
AMD尚未建立与Nvlink媲美的集群互连能力
毫无疑问不会有人用单卡去做LLM,因此相比无实用意义的GPU单片规格的比较,我们更应该关注集群互联的效果。
AMD同步于Q4上市的Instinct MI300X Platform是一个OCP标准整机形态,内置8路MI300X GPU,共计1.5TB HBM3内存。关于MI300X Platform标准机型的机内和机间Pod的互连拓扑,AMD并未明确说明,仅仅谈到了更高速率的Infinity Fabric I/O架构,以及8颗MI300X互连 为一组的标准Node(类似NV的Cube或是GCS的Slice,遵循OCP行标)。以及标准机内累计配置的1.5TB HBM3内存。
AMD想必还没有完成在SuperPod拓扑定型方面的工作,即可能并未解决IMP机内铜缆互连以及Rack-to-Rack机间RDMA的硬件问题(包括机外背板、单级 或多级Switch、DAC/AOC收发端子、线材标准以及协议层和底层通信加速库等等),这就十分不利于MI300X in AIDC场景的生产级部署。如今MI300X呈 现出的纸面规格仅仅证明硬件用料扎实,以及间接反映出单卡Flops/Byte指标的突出,其中有关“多机多卡集群系统 ”的硬件/软件指标仍然未知,这对于 通常的分布式AI/DL workloads以及IDC Pref/TCO都是不利的。因此,MI300X最明显的硬件短板可能就在于多机多卡的集群互连能力;当下无论如何与NV DGX标准节点和SuperPod都是无法相比的,即使单独对比NVLink和NCCL的效能指标也是不具备可比性的。
英伟达对供应链控制
据semianalysis说法,英伟达之所以能够在群雄必至的AI芯片市场一枝独秀,除了他们在硬件和软件上的布局外,对供应链的控制,也是英伟达能坐稳今天位置的一个重要原因。
英伟达过去多次表明,他们可以在短缺期间创造性地增加供应。英伟达愿意承诺不可取消的订单,甚至预付款,从而获得了巨大的供应。目前,Nvidia 有111.5 亿美元的采购承诺、产能义务和库存义务。Nvidia 还额外签订了价值 38.1 亿美元的预付费供应协议。单从这方面看,没有其他供应商可以与之相媲美,因此他们也将无法参与正在发生的狂热AI浪潮。
最近这一次,英伟达又抢走了SK海力士、三星、美光HBM的大部分供应,这是GPU和AI芯片正在追逐的又一个核心。英伟达向所有 3 个 HBM 供应商下了非常大的订单,并且正在挤出除Broadcom/Google之外的其他所有人的供应。此外,Nvidia 还已经买下了台积电 CoWoS 的大部分供应。但他们并没有就此止步,他们还出去考察并买下了Amkor的产能。
7月12日消息,据CNBC、MarketWatch等外媒报导。KeyBanc Capital Markets分析师John Vinh于当地时间10日发布研究报告指出,AMD新一代APU芯片MI300量产可能将延后,这将使得台积电能够释放出更多的CoWoS封装产能,NVIDIA将会从中直接受益,能够获得足够的CoWoS封装产能,从而使得NVIDIA数据中心业务营收在2024年提升到原来的4倍。AMD未来在供应链的竞争中无疑处于劣势。
总体而言,虽然Nvidia的技术护城河足够深,但内存对于运算性能的巨大提升,则意味着Nvidia引以为傲的核心性能也并非不可替代,随着行业开始卷内存和AMD的加入,以及供应链涨价等因素,Nvidia的毛利将会被削弱。微软和特斯拉这类的自用客户虽然不能研发出比Nvidia更优秀的芯片,但如果制造成本跟H100的3000美金拉平。若不考虑能耗则性能只需要需达到H100高达40000美元售价1/10的性能便具备经济性,因此对Nvidia最大威胁的并非AMD而是自用客户带来的售价压力,长期来看AI芯片的毛利会回归到60%的平均水平,但笔者认为Nvidia明年仍将有不少于400亿的净利润,折合当今股价约为30倍的PE,考虑到AI带来的长期成长性其股价依旧合理。
反观AMD普遍预测2025 财年(2024自然年)销售额将再增长 16%,达到 307 亿美元。营业额毛估为Nvidia保守预期的3/8,毛利率大约为5/8,即便不考虑AMD低得可怜的净利润率,其估值也不应超过Nvidia的20%,而目前其市值也刚好为Nvidia的20%左右,并没有明显的估值优势。
大嘴 banker是盛石咨询的策略分享账号,我们是一家致力于全球化资产配置的投资机构,如需付费获取持仓信息或投资基金请可关注大嘴banker公众号联系我们。
英伟达(Nvidia)与AMD在AI领域的技术竞争力对比相关教程
-
 CES 2024丨NVIDIA引领AI汽车技术创新,推动人工智能进一步发展
CES 2024丨NVIDIA引领AI汽车技术创新,推动人工智能进一步发展2024-01-09
-
 AMD为Microsoft客户带来全新AI和计算能力,引领先进技术驱动创新
AMD为Microsoft客户带来全新AI和计算能力,引领先进技术驱动创新2023-11-17
-
 AMD是否能成为英伟达AI服务器的新引擎?
AMD是否能成为英伟达AI服务器的新引擎?2024-02-25
-

- 英伟达的野心,远不止造芯:探索AI创新的未来
- nVidia RTX SUPER GPU震撼发布,AI能力全面升级!-全面提升的AI能力与震撼发布
- Nvidia在2024年的增长和潜力:探索未来科技巨头的发展前景
- 英伟达股价重挫1.8个宁德时代,AI龙头是否面临风险?
- OpenAI宣布与马斯克独立,并与微软直接竞争
- AMD引领AI革命:MI300芯片出货预期达30-40万颗
- 浅谈国产六大CPU芯片厂商:发展现状与前景分析
- 微软秘密开发首个千亿大模型,竟由OpenAI对手操刀!- 一窥微软最新AI技术突破
- 华硕官网泄露AMD锐龙AI 9 HX 170处理器:12核24线程性能曝光
- 国内会有吗?曝英伟达今年仅发布RTX 5090显卡,国内上市情况如何?
- 微软大客户订单激增,美国云计算三巨头继续保持高增长
- 近40亿美元投资,微软在东南亚疯狂加码|SEA Now: 微软在东南亚市场投入巨资,加速扩张
微软资讯推荐
- 1 浅谈国产六大CPU芯片厂商:发展现状与前景分析
- 2 微软秘密开发首个千亿大模型,竟由OpenAI对手操刀!- 一窥微软最新AI技术突破
- 3 国内会有吗?曝英伟达今年仅发布RTX 5090显卡,国内上市情况如何?
- 4 Windows 10市场份额重返 70% Windows 11继续下滑:用户回归主流操作系统
- 5 全新显卡推荐:2021年最佳显卡推荐及性能对比
- 6 NVIDIA已悄悄推出新RTX 4070,改用AD103核心,性能如何?
- 7 今天小编分享 显卡进口攻略!以及显卡进口关税!最新解析
- 8 前白宫网络政策主管:微软是美国国家安全威胁的真相揭露
- 9 微软推出新型AI工具VASA-1,可将照片转化为逼真视频,让您的照片动起来
- 10 英伟达股价重挫1.8个宁德时代,AI龙头是否面临风险?
win10系统推荐
系统教程推荐